Create Personal Access Token
Lyra, Gadi and Setonix (Australian Nextflow Seqera Service)
You need the authentication token to run Tower Agent (Gadi, Setonix) and monitor the pipeline in the Australian Nextflow Seqera Service (Gadi, Setonix and Lyra). The authentication token can be created in Your tokens section of your profile in the Australian Nextflow Seqera Service.
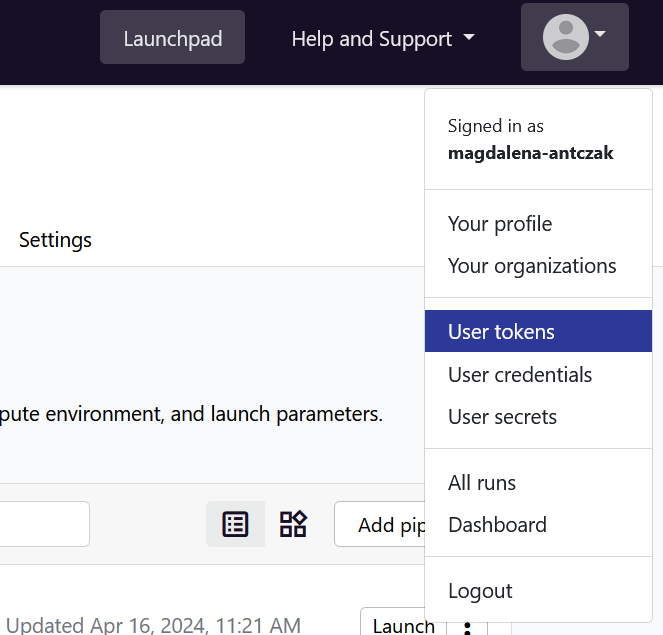
More information on the authentication can be found in the the Australian Nextflow Seqera Service documentation: Authentication (Seqera) and Create Personal Token (Australian BioCommons).
Add Credentials for Tower Agent
Gadi and Setonix (Australian Nextflow Seqera Service)
The Tower Agent needs to be run continuously to pick up jobs from the Australian Nextflow Seqera Service, execute them on the HPC, and to display live output logs and reports upon completion. To run Tower Agent on HPC, you first need to create credentials for the Tower Agent. They will be used together with the Personal Access Token you created in the previous step.
If you are part of an organisational workspace, someone might have already created the Tower Agent credentials and enabled the sharing of the agent. If that is not the case, you will need to create the credentials yourself. Go to the Credentials tab in your organisation’s workspace, check if Tower Agent credentials exist already, and if not, click Add Credentials.
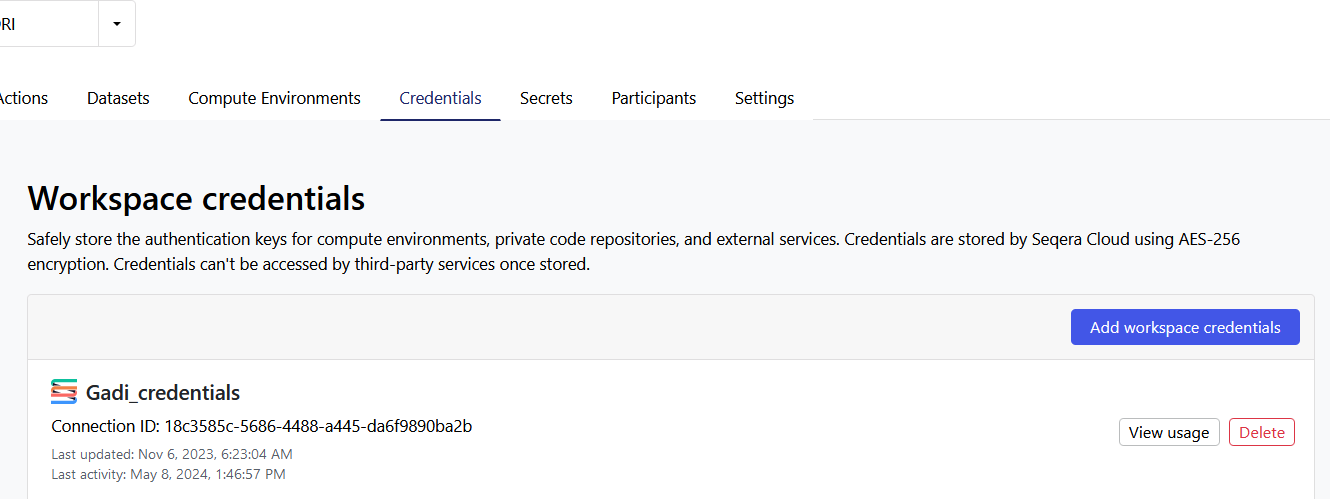
You can also create credentials in your personal workspace.
More information on adding the credentials can be found in the Australian Nextflow Seqera Service documentation from Australian BioCommons: Create Tower Agent credentials.
Usage section. You will need it to launch the Tower Agent in a later step.Lyra
You are only allowed to monitor jobs using the Australian Nextflow Seqera Service on Lyra, which does not require running the Tower Agent.
Add Personal Access Token in GitHub
Gadi and Setonix (Australian Nextflow Seqera Service)
GitHub is very restrictive about the number of times you can make API requests (restrictions are applied when you execute a pipeline in the Australian Nextflow Seqera Service directly from GitHub repository). You can increase that number while using a personal access token - we recommend creating one and adding it to the credentials (below). Instructions on how to generate the authentication token can be found in the GitHub documentation: Managing your personal access tokens.
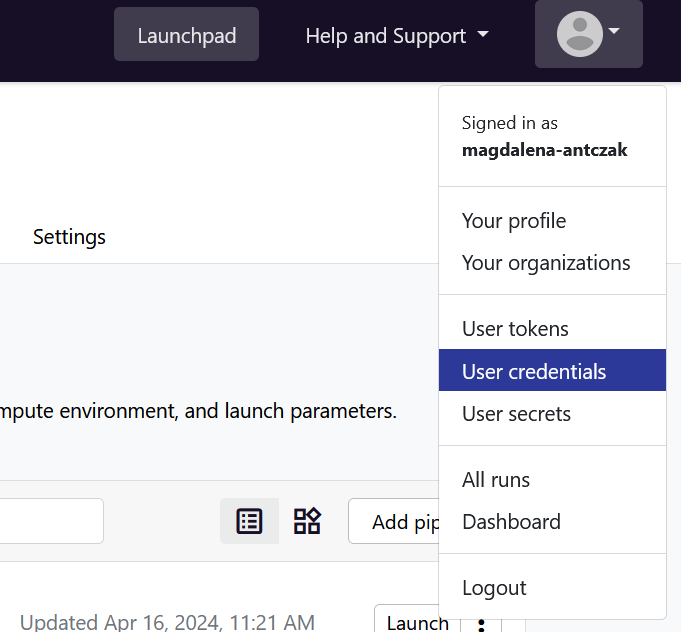
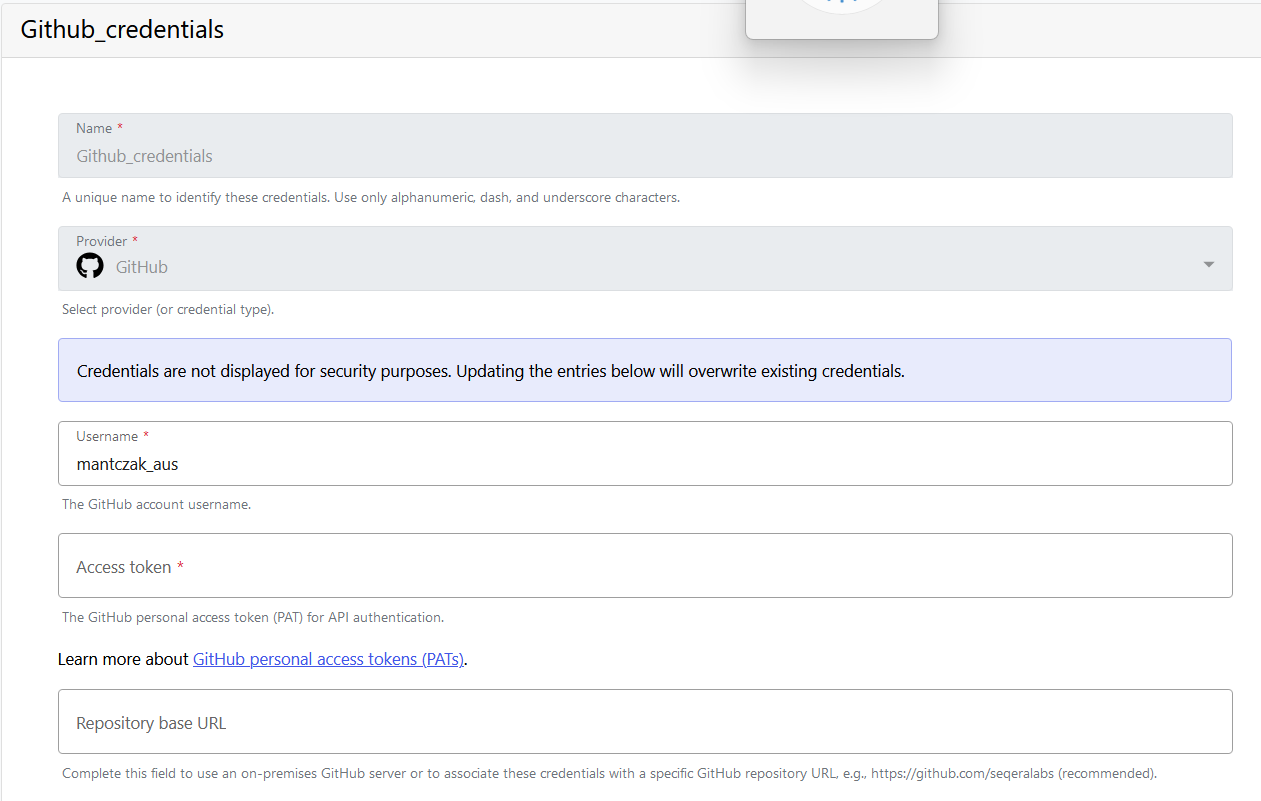
Add Credentials for GitHub
Gadi and Setonix (Australian Nextflow Seqera Service)
Credentials for GitHub are created similarly to credentials for the Tower Agent – you also have the option to add them at the organisation or personal level, and you need to navigate to the Credentials tab. However, instead of choosing Tower Agent as a Provider, you will need to choose GitHub. Fill in the rest according to the help text provided under each field.
Install Nextflow and add default configuration
Gadi
Nextflow is available as one of the modules on Gadi, so installation is unnecessary. You will need to provide other required configuration through the Compute Environment in the Australian Nextflow Seqera Service.
Setonix
Nextflow is available as one of the modules on Setonix, so installation is unnecessary. You will need to provide other required configuration through the Compute Environment in the Australian Nextflow Seqera Service.
Lyra (HPC)
Follow the steps in the NextFlow quick start guide created by the QUT’s eResearch Office:
- Installing Nextflow
- Nextflow’s Default Configuration
- To monitor the pipeline’s execution in the Australian Nextflow Seqera Service, you need to add the following to the ‘config’ file. First, prepare your Personal Access Token and workspace ID (found in the
Your organizationssection of your profile in the Australian Nextflow Seqera Service). Then, paste the following code into your Linux command line and hit ‘enter’:cat <<EOF >> ${HOME}/.nextflow/config tower { accessToken = <YOUR PERSONAL ACCESS TOKEN> workspaceId = <YOUR WORKSPACE ID> endpoint = 'https://seqera.services.biocommons.org.au/api' enabled = true } EOF
Launch Tower Agent
You need to launch Tower Agent before you add a Compute Environment, as well as to add or execute a pipeline. Even if you use the Australian Nextflow Seqera Service on Setonix or Gadi, this step needs to be done on HPC directly. Modify the command you copied from the Usage section when you created the Tower Agent credentials by populating it with your security access token. Then, execute it on the HPC. Tower Agent will populate files in the work directory, so create it before executing the command. The Tower Agent will stop running when you close the ssh session and thus, it is recommended to use a terminal multiplexer like tmux or submit a job with the running agent to the scheduler (more information in the Quickstart section of the Tower Agent help page provided by Seqera). Below the tips and recommendations for running the Tower Agent on Gadi and Setonix.
Gadi (HPC)
Start a persistent session
persistent-sessions start -p <project-id> <session-name>
ssh to the given address, e.g.
ssh <session-name>.<user-name>.<project-id>.ps.gadi.nci.org.au
Start a tmux session and then launch the Tower Agent by using the command provided to you when you created the Tower Agent credentials.
Setonix (HPC)
Both tmux and screen are available on Setonix, so you can launch the Tower Agent like you would on Gadi. Alternatively, you can also submit a job to Slurm that will keep the Tower Agent running for a certain period of time. The following command creates a Slurm script with directives required to run Tower Agent on Setonix. Copy the command, replace the instructions provided to you when you created the Tower Agent credentials, and then submit it to Slurm.
cat <<EOF > run_toweragent.sh
#!/bin/bash -l
#SBATCH --job-name=tw-agent
#SBATCH --mem=12gb
#SBATCH --time=24:00:00
#SBATCH --cpus-per-task=2
#SBATCH --partition=work
#SBATCH --ntasks=1
#SBATCH --ntasks-per-node=1
cd ~
<INSTRUCTIONS PROVIDED TO YOU WHEN YOU CREATED THE TOWER AGENT CREDENTIALS>
EOF
Once the run_toweragent.sh file is created, submit it to Slurm by executing the following command in your command line
sbatch run_toweragent.sh
Add a Compute Environment
You are now ready to create a Compute Environment. Some general tips and instructions on how to add compute environments can be found in the Australian BioCommons documentation and in the Seqera help pages. Below are instructions on what to fill in the specific fields to run the ONTViSc pipeline on Gadi and Setonix. You can create a compute environment in your personal or organisational workspace. To do that, click on your user name in the top left corner of the page, select the corresponding workspace and then navigate to the Compute Environments tab.
Name
Provide a name according to the given instructions.
Platform
Gadi
Altair PBS Pro
Setonix
Slurm Workload Manager
Credentials
Gadi and Setonix
Select the Tower Agent credentials you created in one of the previous steps.
Work directory
Gadi and Setonix
Specify a directory where all the task work directories will be created (more information on the work directory in the Nextflow documentation and Nextflow basic training). This can be overwritten later when the pipeline is being created and executed.
Launch directory
Gadi and Setonix
After the pipeline is launched from Australian Nextflow Seqera Service, a script submission to the scheduler will be created and submitted on your behalf on the HPC. The Launch directory will store all those scripts, configuration files and logs. You can specify it or leave it empty (it will be populated with Work directory in the latter case).
Head queue name
Gadi
copyq
Setonix
work
Compute queue name
Gadi
Leave empty.
Setonix
work
Staging options: Pre-run script
Gadi
module load nextflow/24.04.1
module load singularity
Setonix
module load nextflow/24.04.3
module load singularity/4.1.0-slurm
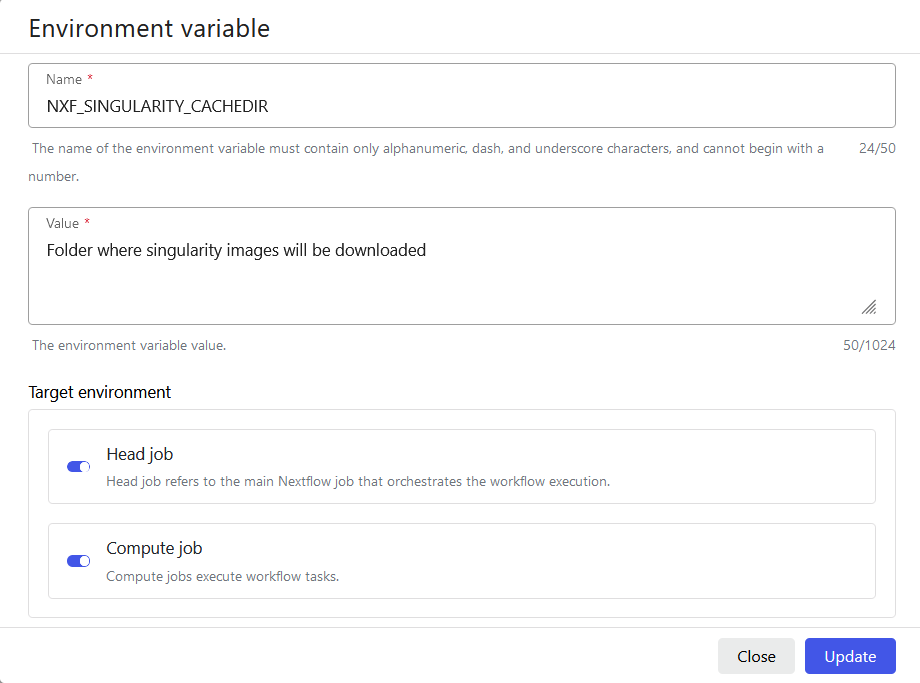
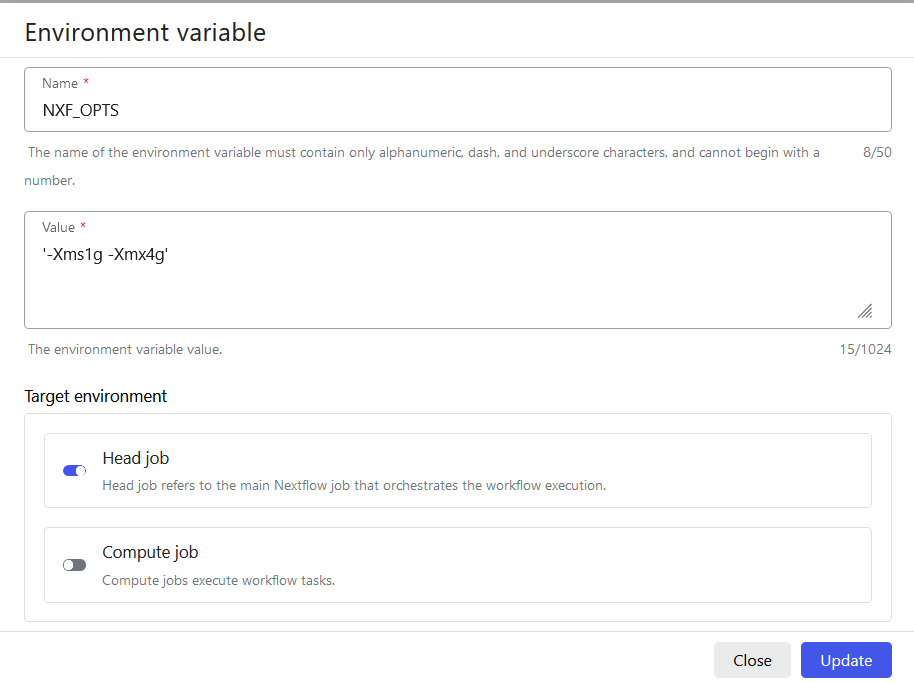
Environment variables
Gadi and Setonix
Add the environment variables like in the screenshots below.
Advanced options: Head job submit options
Gadi
Copy and paste the following text. Replace the
-l walltime=10:00:00,ncpus=1,mem=32gb,storage=scratch/<project-id>+gdata/<project-id>,wd -P <project-id>
If you are a part of the if89 project and want to use its databases, you need to link that location as well via -l storage directive, i.e.
-l walltime=10:00:00,ncpus=1,mem=32gb,storage=scratch/<project-id>+gdata/<project-id>+gdata/if89,wd -P <project-id>
Setonix
--mem=32G --cpus-per-task=8 --time=24:00:00
out of memory error when downloading the singularity images of the tools.Add a pipeline
Some general tips and instructions on how to add a pipeline can be found in the Seqera help pages. Below are instructions on what to fill in the specific fields to run the ONTViSc pipeline on Gadi and Setonix. Similarly to compute environments, you can add a workflow in your personal or organisation workspace. Just click on your user name in the top left corner of the page, select the corresponding workspace, and then navigate to the Launchpad tab.
Name
Provide a name according to the given instructions.
Compute environment
Select the Compute Environment you just created.
Pipeline to launch
https://github.com/eresearchqut/ontvisc
Revision number
Choose main or any other revision you want to execute.
Work directory
It should be pre-populated from the Compute Environment.
Config profiles
Select singularity.
Advanced options: Nextflow config file
Gadi
process {
beforeScript = 'module load singularity'
storage = 'scratch/<project-id>+gdata/<project-id>'
}
If you are a part of the if89 project and want to use its databases, you need to link that location as well:
storage = 'scratch/<project-id>+gdata/<project-id>+gdata/if89'
Setonix
process {
beforeScript = 'module load singularity/4.1.0-slurm'
}
singularity {
cacheDir = '<A FOLDER WHERE THE SINGULARITY IMAGES WILL BE DOWNLOADED>'
}
Advanced options: Pre-run script
It should be pre-populated from the Compute Environment.